
按:此文原载于2024年10月少数派首页推荐文章 《带着数字化"摘录者"重返纸质阅读》
前言 #
伴随社会数字化的进程,似乎很多传统实体渐渐淡出我们的视野甚至已经消亡。关于读书方式,关于笔记方式,一遍又一遍地被科技进步颠覆。依稀记得求学生涯搬家时,多次不堪书籍之重负;十几年前,花重金购入了Kindle Voyage,以为掌握了读书的终极神器;再到后来,渐渐抛弃了Kindle,拥抱了手机和平板阅读。时至今日,我仍然怀念纸质书籍,它真实的触感和气味,给人一种空间感、沉浸感和亲切感。这种阅读记忆是立体的,深刻的,是我在电子化阅读中一直没有找到的感觉。
不可否认,数字化的便利是无可替代的。虽然我把早年的手写笔记做成了扫描件,更是随着我的电子笔记系统辗转迁移,但最终还是由于难以检索而躺在了“最近访问”的最下层。
我在思考,现在有没有能兼具纸质阅读和数字化笔记的方法呢。我找到了一些朋友们实践,比如:
- 阅读时,直接在书本上做标记,读完后再统一摘抄出来,使用键盘输入摘抄,或语音输入摘抄;
- 边阅读边使用手机app ocr,如自带相机,白描,Office Lens,Readwise等应用识别并手动拾取文字;
- 使用智能硬件进行文字摘抄,如扫描笔;
似乎一切方案都不那么完美,要么有点打扰阅读,要么读后的整理工作太繁琐,要么没法摘抄图片。有没有方法可以克服这些问题呢?经过搜索调研,我初步设想了一种使用机器视觉的方法来辅助阅读摘抄。既然是机器视觉,当然还是使用ocr,但现在的ocr方法需要我们“拿起”手机—“端正”手机—手动拾取,目的是提高ocr的成功率。所以关键是如何简化该流程,尽可能地实现自动化,最好只需要“随手一拍”,最完美的是“不要拿起手机”。
 如何自动化摘录?
如何自动化摘录?
我现在的目标是解决碎片化的原文摘录问题,关于笔记书写和录入,能在更集中的时间和版面内完成,方法也更简单,暂时不在本文讨论范围。又,本文不讨论读书方法论,不讨论摘录是否有价值的问题。
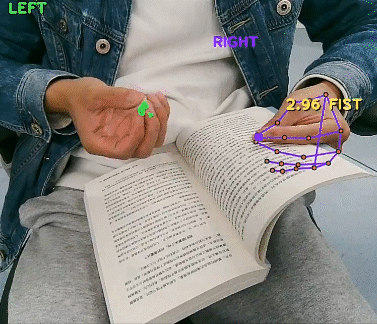 手势触发摘录
手势触发摘录
 后台迭代计算与摘录
后台迭代计算与摘录
问题的关键——去扭曲 #
要提取书摘,首先要提高ocr的成功率,但书籍表面往往不是平面,且书籍方向不正,大大降低了ocr成功率,后续的文字提取也无从谈起了。即使是白描这样优秀的ocr软件,在这样苛刻的工况下,不进行扭曲矫正也难以做到很高的ocr正确率。
 白描 OCR,大角度拍摄造成的文本错行
白描 OCR,大角度拍摄造成的文本错行
文档图像的变形有扭曲、褶皱、透视等多种情况,这阻碍了形变图像的信息提取,对下游任务如OCR识别、版面分析等任务增加难度。为解决文档弯曲矫正问题,学界业界已有多种方案:
- 利用多目相机,结构光或者激光雷达等专用硬件对文档进行扫描,获得文档表面的3D结构信息,进而对文档校正展平。这类方法一般可以得到比较好的校正效果,但依赖专用设备的特点限制了其使用场景,一般应用在高拍仪上。
- 利用显式的几何模型以适应形变文档曲面,依靠图像信息以及文档形变的先验知识对图像进行校正。一般需要进行文字行或者表格线的检测,并假设曲面符合特定的几何约束,如曲面是柱面。其校正效果受文字行检测准确度的限制,对文档版式比较敏感,无法处理存在大量图表的文档,且误检的文字行有可能会对校正造成严重干扰。
- 基于优化的方法,利用损失函数缓慢迭代优化以获得形变矫正结果。
- 数据驱动的方法。训练形变矫正神经网络,学习形变场,得到类似扫描的结果。
总结下来,去扭曲解决方案可分为参数化方法及非参数化方法。参数化方法构建了低维数学模型,只能处理简单场景;非参数化方法一般需要建立成对数据集。在2024年,我们当然首先要尝试一下基于深度学习的方案,包括了DewarpNet、DocGeoNet、DocTr、DocTr++等等,这些工作多关注于通用文档校正,但对于我们这个应用场景,实际效果都不太好,且大多项目由于商业因素,没有开源。实测下来,合合的文档图像切边矫正效果是最好的,但有时也会出现很怪的大畸变,合合方案调用api使用,按量付费。
书籍具有相对固定的形态、比例,且表面是连续平滑的,这些约束极大降低了问题的复杂度。针对书籍的去扭曲,比较有名的是 mzucker/page_dewarp开源项目,通过样条拟合书表面的形状,通过迭代优化,减少重投影误差。该方法中,书表面尽可能垂直于相机光轴,否则容易产生透视畸变,还要求相机尽可能少的横滚角,以免文本行提取失败。page_dewarp处理图片耗时较长,20秒左右,大部分耗时在迭代计算环节。
 mzucker/page_dewarp
mzucker/page_dewarp
 表面扭曲与文本行变形
表面扭曲与文本行变形
最后,找到了Document dewarping via text-line based optimization这篇文章,最适合解决我的需求。通过文本行估计表面形状,构建损失函数,通过牛顿迭代法找到最优的变换参数,这个方法假设了:1.文本是水平的;2.在同一个文本块中,两个相邻文本行之间的行距应该是恒定的;3.大多数文本块是左对齐、右对齐或两端对齐的。这些假设也限定了我们的应用范围:书籍内容以横排文本为主。这个方法运行速度很快,耗时秒级,且成功率非常高。具体的处理流程我们放在下节说明。
还有很多桌面/移动应用也提供了去扭曲的功能,具代表性的有ABBYY FineReader、ScanTailor-Experimental、ComicEnhancerPro、VFlat、扫描全能王。这些应用的处理速度很快,但对拍摄偏角大的图片往往就失效了,一般还是应用在扫描质量高的图片中,进行后期微校正。
以下是上述方法的测试情况。仅定性比较,非严谨对比,部分输入和输出图片有裁切,ComicEnhancerPro为手动调整控制点。对于拍摄角度正的图片,大多软件都有可观的结果,对于拍摄角度大的图片,只有合合方案和Kim的方法有较好的效果。虽然有时参数化方法不一定得到最佳效果,校正后的图片总体还是平滑的;而基于深度学习的方法有时结果扭曲得厉害,翻看论文,感觉这类方法还是更擅长处理褶皱的文档,可能是数据集的原因,也可能图片需要预处理。
 非严谨对比 1
非严谨对比 1
 非严谨对比 2
非严谨对比 2
如何实现 #
为了稳定地实现书摘的提取,我设计了一个流程,由“分割”-“去扭曲”-“光照校正”-“标记提取与OCR”组成。对待提取的文本和图片,我们预设了两种标记:下划线用于提取文字,拇指食指指尖位置用于标记提取段落或图片。
 自动化流程
自动化流程
分割 #
为了提高系统在自动运行时的可靠性,需要尽可能排除环境干扰。我们直接使用Yolo对书籍目标进行分割,我们对分割的效果要求不高,只需粗略将书籍分离出来,即使是small模型也可以满足要求。
在去扭曲的环节中需要提取文本行特征,一般来说通过文本行特征可以完成书籍“左页”和“右页”的分离,但在书本旋转角度过大或左右页文字相隔太近时,该方法就失效了。因此我们加了一个分离书籍“左页”和“右页”的模块。该模块以Yolo的分割结果作为输入,通过掩膜缩放、二值化处理、轮廓识别、形态学操作等步骤,首先尝试寻找书籍的中缝,以中缝为界分离“左页”和“右页”;如果光照比较均匀且书籍较薄时,中缝寻找失败,则遍历旋转角度-45°~-45°,估计中缝和旋转角度。
 含中缝,书籍较厚或斜向光照(左);不含中缝,书籍较薄或光照均匀
含中缝,书籍较厚或斜向光照(左);不含中缝,书籍较薄或光照均匀
结合Yolo的分割结果和中缝数据,我们就可以将书籍“左页”和“右页”干净地分离出来了。
去扭曲 #
我们基于优化的方法对书本进行形变矫正。详细的过程可以参考论文和代码rebook。由于本人水平有限,没有完全按照原文构建pipeline,但实际测试下来,校正结果尚可,再此基础上,我做了二阶段处理:根据文本行重新校正纵向的偏差,根据文本行左右边界校正水平倾斜。结果也是基本满足我们强力约束的:文本水平、行距恒定、两端对齐。
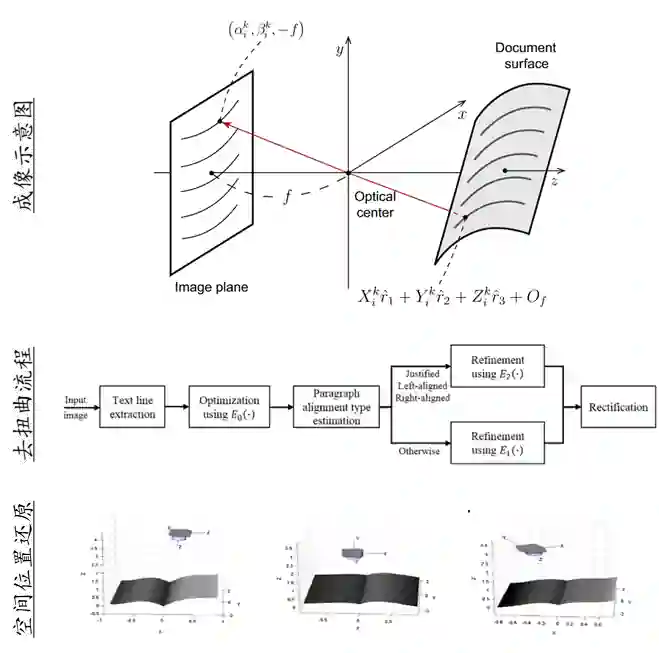 Dewarp流程与基本概念
Dewarp流程与基本概念
光照校正 #
对去扭曲的图像进行切边和光照的校正,我们就得到了一张等待ocr的图片啦。光照校正分两种情况,一种是文本类,我们采用类似扫描类app中的“背景去除”功能,将背景设置为纯白,根据前景/背景比值重新映射前景值,这种方法也可以去除大面积的阴影,代价是损失一些对比度;一种是图像类,“背景去除”会将图片中的大色块清除,因此,对于图像类,我们仅进行白平衡和亮度的调整。
 去大面积阴影
去大面积阴影
 对图像和文本的不同处理方法与对比
对图像和文本的不同处理方法与对比
标记提取与OCR #
对目标文本和图片,我们预设了两种标记,即下划线和指尖位置。代码中,我在去扭曲校正环节,已经将指尖坐标点也做了映射,并在提取文本行时将下划线提取出来了,因此在该环节,我们只需根据该标记选择性地进行文本ocr或图片处理。
下划线标记的提取原则很简单,即提取线上的文本,并根据缩进和段落,对每行文本重新组织段落。
指尖标记。若只有一个有效指尖坐标,则提取其指向的文本行,提取结果为整行文字。若有两个有效指尖坐标,分析这两个坐标的y值间的内容,若文字密度大于预设的阈值,则提取两个y值间的所有文本;若文字密度小于预设的阈值,则判定为插图,仅裁切而不进行ocr。
同时,通过分析首尾3段文本行,提取出页码。将原图、校正图、ocr文本、插图、页码按照markdown格式保存,我们就获得了该页的电子书摘。
 文本提取(左);Markdown 格式摘录
文本提取(左);Markdown 格式摘录
离线与在线运行 #
离线运行程序代码托管在Github上。
Github
osnsyc/Excerptor
离线运行适合任何阅读场景。只需要将待摘抄的书页拍摄下来,运行程序,程序对图片进行统一处理,输出为markdown格式的文档。在该场景下,我们可以选择用彩色标签标记段落,最后统一拍摄、处理;也可以阅读时随时拍摄,最后统一处理。批量处理图片,平均每张耗时低于10秒。
 彩色标签
彩色标签
在线运行,我们需要利用边缘设备,搭建一个“读书场景”。我将程序部署在Orangepi 5 pro上,摄像头采用CMOS尺寸1/2’‘的5000万像素USB摄像头。该场景下,我们可以“实时”地做书摘。我在之前的文章 在家做一个魔法师,智能家居也可以动"手"不动口中, 演示了如何在Orangepi上做一个手势控制智能家居的控制器,我将该控制器也融合进了这个项目中,使用预编程的手势触发信号,控制器收到信号后,在固定的延时(5秒)后拍摄图片,并进行书摘的提取, 输出为markdown格式的文档。为了极致的自动化,我们也可以将markdown文档直接保存在Obsidian库中,或着通过api调用同步至在线笔记中。
手势触发摘录
后台迭代计算与摘录
结尾 #
本文是我在探索读书笔记数字化过程中的粗浅实践,还有很多不完善之处,比如,最终的OCR结果不是100%正确,手指拾取文本只能做到整行提取。未来可能进行的优化工作有:
- 结合电子书文件对OCR结果进行校正;
- 手指拾取文本行后的智能断句;
- 复杂排版书籍的扭曲校正;
- 手写注释的提取;
值得一提的是,在本文成文时,我发现微信读书有个“连接纸书”功能也可以对书本内容进行匹配和对下划文本进行识别。或许可以把微信读书也融入到自动化流程中。最后,贴一些图书数字化的图以飨读者,并附上我在实践中看到的好文好物。
 纵向图文混排
纵向图文混排
 手指段落提取
手指段落提取

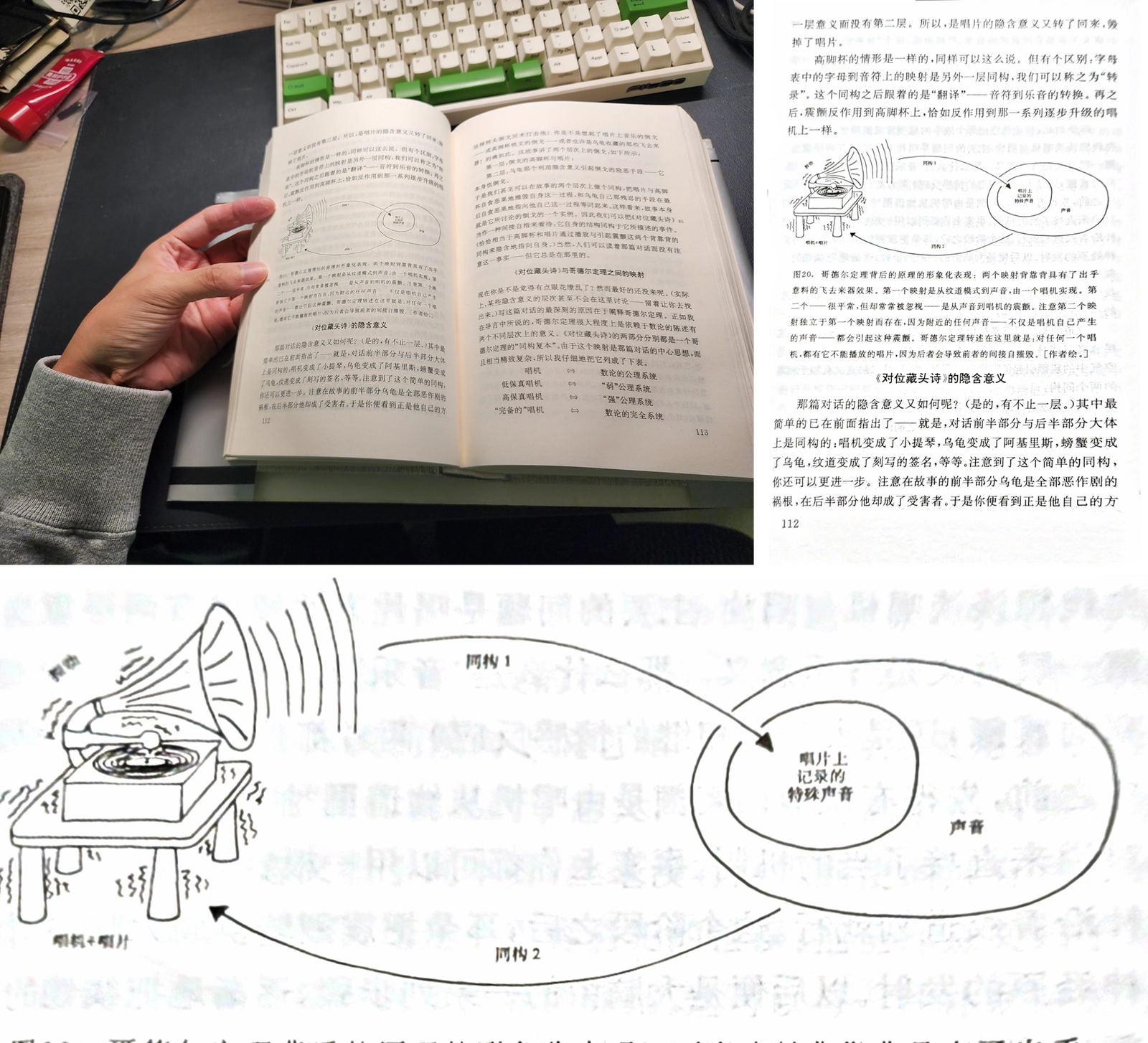 手指图片提取
手指图片提取
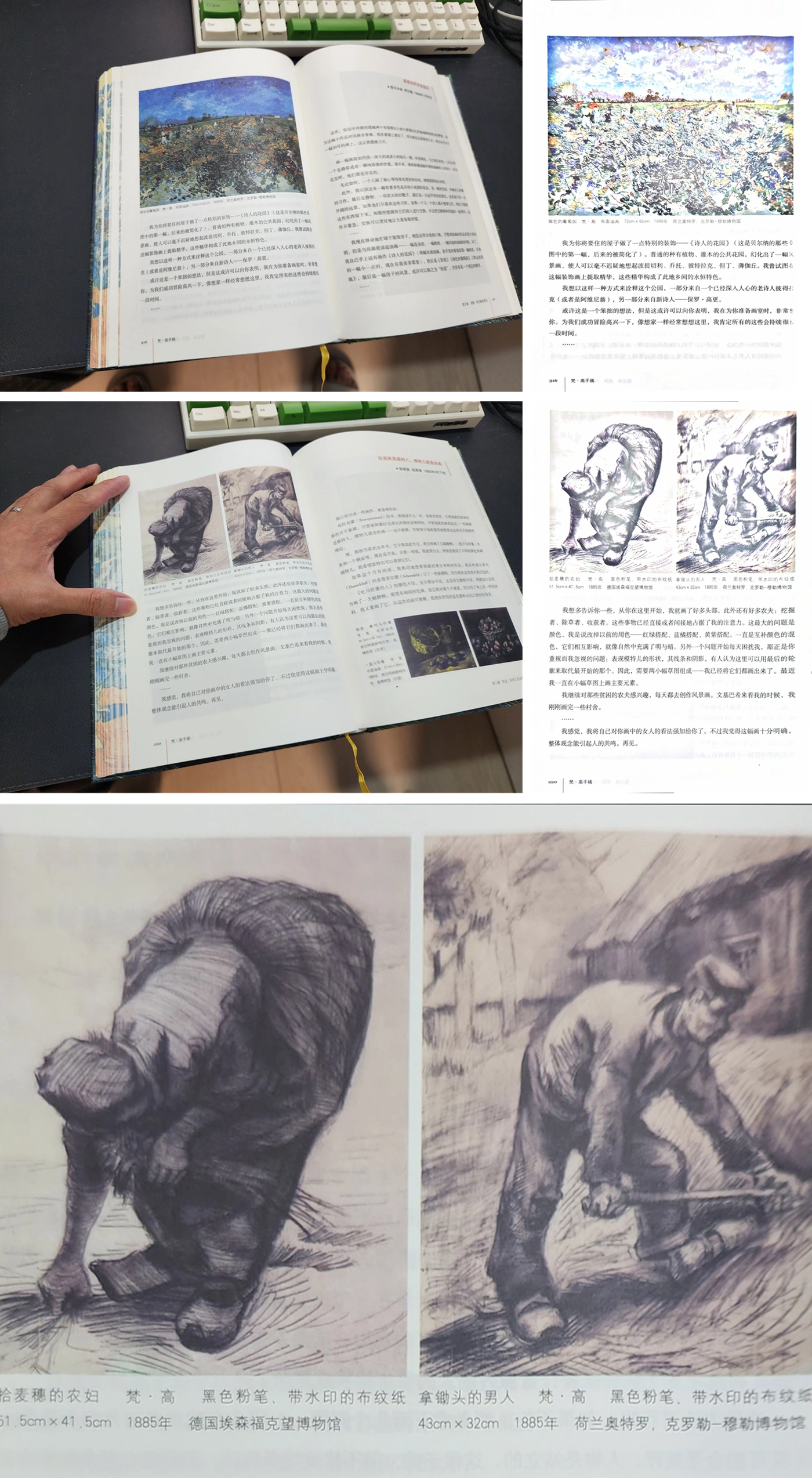 不同的图像处理效果 与 手指提取图片
不同的图像处理效果 与 手指提取图片
附录 #
Digitalize notes #
- How do you efficiently take notes from physical books? : r/ObsidianMD
- Digitalize notes from books : r/ObsidianMD
- Highlighting a physical book - Mickey Mellen
- Best way to capture physical book notes into Obsidian? : r/ObsidianMD
- 原创|纸质书笔记电子化-简单高效版 - 小红书
Methods #
- Page dewarping
- Extract Highlighted Text from a Book using Python - DEV Community
- ComicEnhancerPro 系列教程 附录七:CEP处理之弯曲页面自动展平 - strnghrs - 博客园
- 15 Tools for Document Deskewing and Dewarping
- 弯曲矫正技术概述 - 哔哩哔哩
- Dewarp 文件恢复技术& ROP 阅读顺序预测-CSDN博客
- Text-line based Document Dewarping via Direct surface Reconstruction
- 文本图形处理(扭曲变形、增强等)的源代码列表-2_revisiting document image dewarping by grid regula-CSDN博客
- GitHub - FelixHertlein/contour-based-image-rectification: A small library to rectify masked images based on the mask contour
- Methods To Sense The 3D Surface/Structure Of A Book - DIY Book Scanner
- 文档布局分析 & 扭曲文档图像恢复 — Document Layout Analysis & Document Image Dewarping | S1NH
- Dewarping Documents with AI - Fritz ai
- 仿照“全能扫描王”的图像增强-由原理到实现 - jsxyhelu - 博客园
- GitHub - sbrunner/deskew: Library used to deskew a scanned document
- unpaper/doc/image-processing.md at main · unpaper/unpaper · GitHub
App #
- PDF Scanner | vFlat Scan
- 白描App
- GitHub - Scan Tailor Experimental
- ComicEnhancerPro
- FineReader PDF
- 扫描全能王
- Readwise importing highlights
- Highlighted: Book Highlights on the App Store
Online demo #
- 图像矫正-图片倾斜矫正-图片自动校正-TextIn
- TextIn - 在线免费体验中心 - 文档图像切边矫正
- DocGeoNet - a Hugging Face Space by HaoFeng2019
- DocTr-Plus
- DocScanner