
按:使用手势“隔空”控制智能家居项目“Gesture-Based-Home-Automation”,在香橙派上实现,具有支持多人场景,低延迟,长距离,空间定位,复杂手势组合,支持左右手识别与跟踪等特性。此文原载于2024年7月少数派首页推荐文章 《在家做一个魔法师,智能家居也可以动"手"不动口》
前言 #
相信很多读者和我一样,都有一个巫师梦,等着自己的那只猫头鹰送来霍格沃茨的入学通知书。世界各地的麻瓜们也在乐此不疲地使用科技构筑自己的魔法世界。
前段时间B站就有一个视频大火,使用自制魔杖控制家居设备,很是浪漫!但是从实用角度看,还是邓布利多和伏地魔的无杖施法更吸引人,本麻瓜当然更向往这种高阶法术(不是)。
 《哈利·波特与火焰杯》
《哈利·波特与火焰杯》
无杖施法虽然摆脱了魔杖,但还是至少要挥一挥手,摆个Pose的。那么是否有识别我的姿态和手势,来理解我的意图的方法呢。
经过调研,使用机器视觉是一个可行的方案,我发现不少人已经做了相关尝试,甚至商用摄像头也初步做过简单手势控制功能。而大多数开源项目采用Mediapipe方案,这是一个Google开源的手势识别套件,使用简单,但缺陷在于仅支持单人、近距离识别。1且多数项目仅仅在PC上调用Mediapipe库做了一些简单的特性演示,没有进一步扩展实用功能。
我曾计划在自己的服务器上实现该项目,但考虑到项目对实时性要求高,采用了边缘计算(Edge Computing)方案。对物联网而言,边缘计算意味着许多控制将通过本地设备实现而无需交由云端,大大提升处理效率,由于更加靠近用户,还可提供更快的响应。但是,边缘设备上部署需要克服额外的困难,包括模型的转换与调整,精度与实时性能的权衡。
最终,基于边缘设备(香橙派),我开发了一个手势自动化项目,“Gesture-Based-Home-Automation”。
效果展示 #
“Gesture-Based-Home-Automation”的关键特性有:
- 支持多人场景。通过“抬手”动作触发手势识别;
- 低延迟。手势识别延迟30ms,“抬手”检测延迟50ms,低延迟能更好地支撑复杂手势并提高“跟手”体验;
- 长距离。能识别超过5米距离的手势信号,大体能覆盖单个空间;
- 空间定位。能粗略地识别人体、手部在空间中的位置;
- 复杂手势组合。支持左右手识别,支持5种静态手势、4种动态手势、4种触发模式,通过相互组合并结合手部旋转状态、空间位置,可以定义无穷种手势信号;2
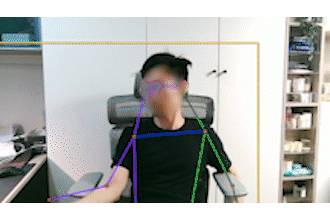 静态手势
静态手势
 旋转状态
旋转状态
 左右手识别与跟踪
左右手识别与跟踪
 远距离识别
远距离识别
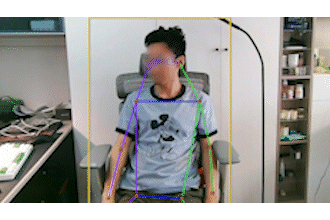 抬手触发识别流程
抬手触发识别流程
 OK 手势开关灯
OK 手势开关灯
 空间定位
空间定位
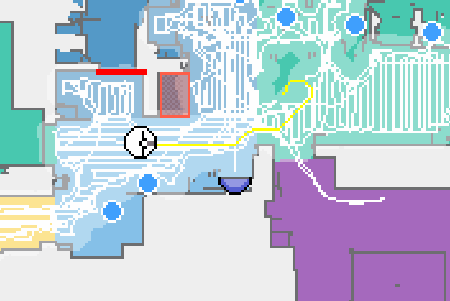 扫地机器人呼唤
扫地机器人呼唤
硬件概况 #
硬件组成:一个香橙派5Pro (Orange Pi 5 Pro)3,一个5V4A电源,一个USB摄像头。Orange Pi 5 Pro。尺寸89mmX56mmX1.6mm,采用了瑞芯微RK3588S处理器,四核A76+四核A55,主频2.4GHz,集成ARM Mali-G610;内嵌的NPU支持INT4/INT8/INT16混合运算,算力6TOPS,4GB LPDDR5,Wi-Fi5、BLE。支持Orange Pi OS、Ubuntu、Android12、Debian等操作系统。摄像头为无畸变86°视角,1080P/30FPS的USB摄像头。
这颗6TOPS的NPU是选择香橙派5Pro的主要理由,我们需要在上面做各种神经网络推理,同时它的价格足够低。
 香橙派 5 Pro
香橙派 5 Pro
手势识别流程 #
在家居场景中,我们的关键需求是全天候运行、使用流畅。具体分析下来,手势使用频率相对不高,这决定了我们并不需要时时刻刻获取手势信息,而为了兼顾长时间运行,设计了这样一个流程:
- 常规时间中,运行多人人体关键点检测,输出人体关键点和框。该阶段的特点是资源消耗低,实时性较差(约50ms),主打一个够用就好;
- 当任一一只手腕高于肩部时,停止人体关键点检测,同时在该人体框内进行手部检测,根据人体关键点匹配左右手,将裁剪的手部图像传入手部关键点检测。该阶段为过渡阶段,耗时约20ms,将人体关键点检测转换为手部关键点检测,同时输出该帧的头部位置与大小;
- 启动多线程检测手部关键点(最多2只手),识别手势,同时预测下一帧的手部位置。只要手部检测的置信度足够高,会一直保持在该阶段,该阶段资源消耗较高,实时性较强(约29ms),对于30FPS的摄像头而言,几乎可以跑满帧率。快速移动手掌或遮挡双手,或双手都丢失预测位置,自动回到人体关键点检测流程。
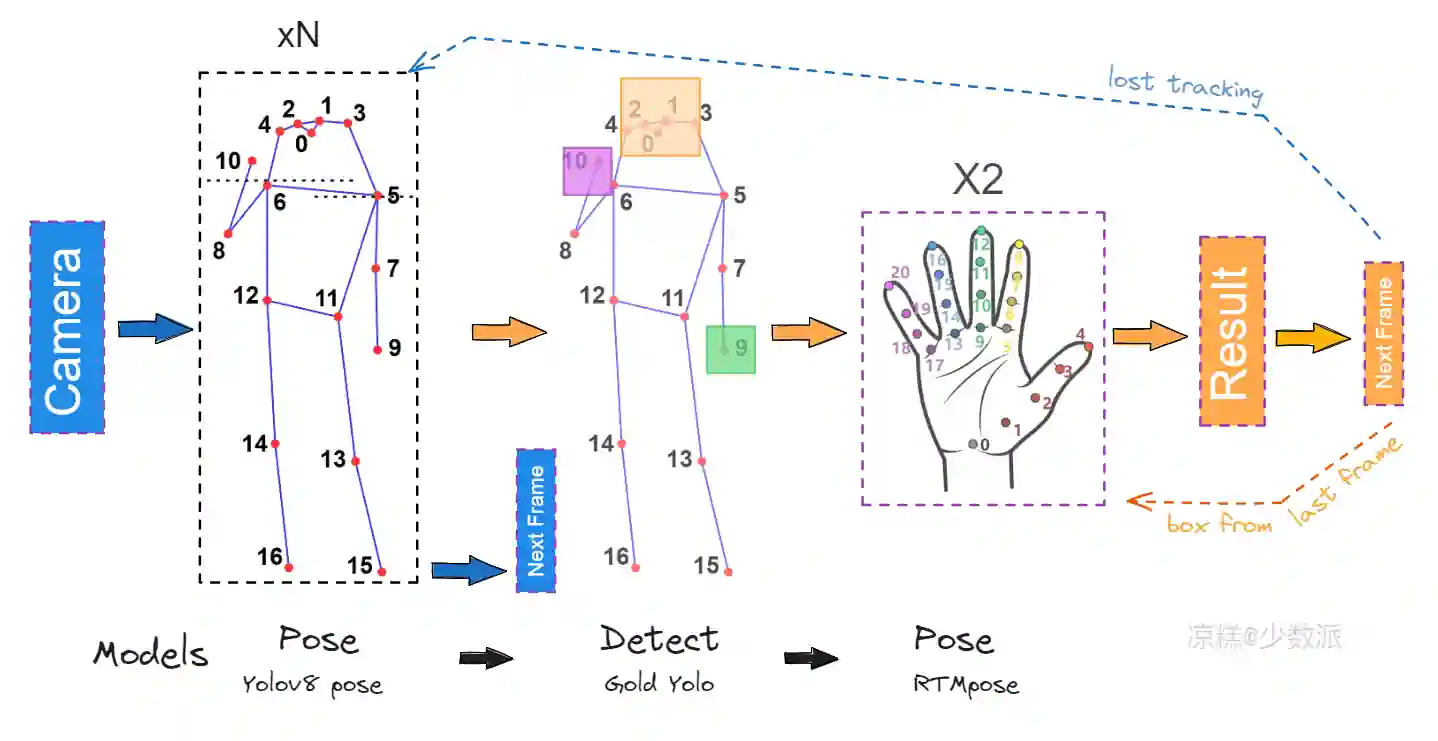 手势识别框架
手势识别框架
在常规时间中(生活中的绝大多数时间),系统保持较低的功耗运行。需要手势控制时,又能快速切换模式,并实时地检测。设计切换信号(手腕高于肩部)可以避免误触发。基本满足了全天候运行、使用流畅的需求。小目标的检测往往是具有挑战的,通过人体框的裁剪,采用Top-Down模式,实现最远5米的手势识别,基本可以覆盖屋内的环境了。
模型选择方面,个人水平有限,考虑到时间成本,贯彻了”拿来主义“,搜刮了一些优秀的模型。但在过程中,转换为3588NPU的模型格式时,又出现了各种问题,包括rknn的各种bug,算子不支持等。后续会根据需要更换模型。当前版本的模型选择如下:
- 多人人体关键点检测:Yolov8 pose (nano),转换为rknpu模型rknn,使用int8量化,追求较高的速度而牺牲精度;
- 手部与头部检测:Gold Yolo (nano),fp16,输出的手部位置为第一帧位置,要求相对高的精度;
- 手部关键点检测:RTMPose (m),fp16,同时要求高精度和高速度。
空间位置估计 #
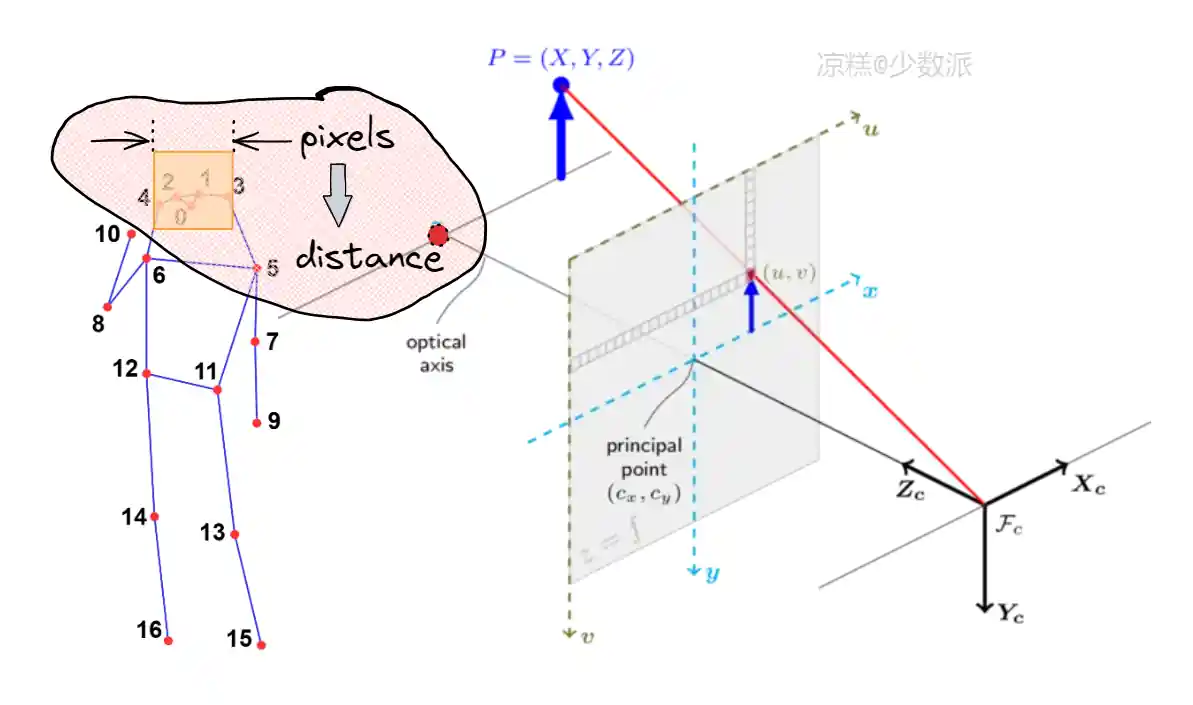
为了获取目标在空间中的位置,需要先估算深度,即目标距相机的距离(光轴方向)。常用的深度估计方法主要包括双目视觉深度估计和单目视觉深度估计。双目视觉使用两个相机,类似于人类的双眼。通过捕捉从两个不同视角的图像,利用视差来估计物体的深度信息。单目视觉的挑战在于,单个相机只能提供二维图像,没有直接的深度信息。因此,需要借助一些额外的信息来推断深度,如通过训练深度神经网络,利用标注数据来学习从单目图像中估计深度;利用物体的已知尺寸、平行线的消失点、阴影等几何特征来推断深度;通过分析物体在多帧图像中的移动情况来估计深度。
 空间位置估计
空间位置估计
双目相机比单目相机贵得多,我想控制住预算,同时,我们只要十分粗略的空间位置,对精度要求很低。通过实验发现,在多数生活情况下,Gold Yolo识别出的头部检测框宽度相对稳定(即使头部发生旋转),因此我们使用头部的宽度信息来标定人体距离相机的深度。获取头部宽度像素数,进而得到人体深度值,与相机的视角、拍摄像素计算,可以得到(x,y)坐标,组合得到每个手掌的(x,y,z)坐标值。该值为相机局部坐标系下的坐标,通过坐标变换,转换为全局坐标系下的坐标值:只需预设相机x轴和y轴在全局坐标系中的向量、相机原点在全局坐标系中的坐标值即可,分别为“vector_x”、“vector_y”和“vector_o”。
手势控制信号 #
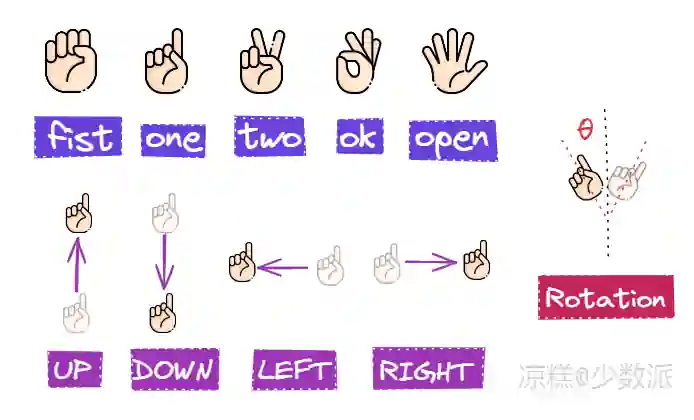
获取手部的21个关键点坐标后,通过计算关节点的弯曲角度得到每个手指的弯曲状态(弯曲或伸直),组合每个手指的弯曲状态,定义了5种手势:“握拳”/“fist”,“一”/“one”,“二”/“two”,“三”/“ok”,“五”/“open”。由于拇指非常容易被遮挡,其弯曲状态容易误判,因此在这5种手势的判断过程中,拇指的状态不纳入考虑,即“四指张开”=“五指张开”。
 基础手势控制信号
基础手势控制信号
使用手掌的关键点(0、5、9、13号关键点),计算得到手掌的“旋转角度”/“rotation”。从人的视角看,五指竖直向上为0,逆时针为正,顺时针为负,单位为弧度,范围(-pi,pi)。
记录每一次检测的食指指尖坐标,获得手指移动轨迹,用线性回归拟合趋势线,根据纵横比和趋势线系数判断手势,分类为4种轨迹“上滑”/“UP”,“下滑”/“DOWN”,“左滑”/“LEFT”,“右滑”/“RIGHT”。拟合趋势线前会移除离群点,增加判断的准确性。轨迹判断具有冗余度,允许轨迹有一定倾角。这里只预设了最简单的4中轨迹,读者可以根据需要自行编写判断轨迹类别(如顺时针、逆时针)。对于更为复杂的手势,可以参考 hand-gesture-recognition-using-mediapipe项目,训练轨迹分类模型。4
总结下来,单次单手检测具有5种手势 x 4种轨迹 x N种旋转角度类别,通过左右手的组合以及空间位置的判断,可以获得数千种手势控制信号。
高级手势与智能控制 #
现在我们已经能获取每一个时刻的手势信号了,即使对检测结果已经进行了初步处理,但是还是会有一些漏检误检。除此之外,我们还要将人类习惯的动态手势转译为控制信号。这里参考 GitHub - geaxgx/depthai_hand_tracker)构建了一个HandController类。
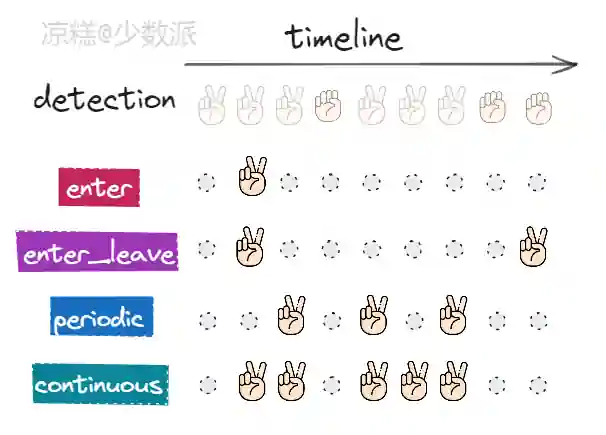
HandController基于事件循环,提前在配置中定义一个手势动作列表。手势动作将手势(例如,右手的OPEN姿势)与回调(识别手势时调用的函数)相关联。根据回调的运行时间和频率设置了4个模式:
- enter(默认):当手势开始时,触发一次事件;
- enter_leave:触发两个事件,一个是手势开始时,一个是手势结束时;
- period:只要手势保持不变,事件就会定期触发;
- continuous:每一帧都会触发事件。
 触发模式
触发模式
同时引入以下三个参数:
- first_trigger_delay:由于手势识别中会出现误报,我们通常不希望在识别姿势的第一帧上触发事件。以秒为单位的“first_trigger_delay”指定手势在触发相应事件之前必须保持多长时间;
- next_trigger_delay:当模式为period时,两个连续事件之间的延迟(以秒为单位);
- max_missing_frames:由于模型并不完美,因此会出现假阴性。比如,手在 20 帧中保持着“ONE”手势,但模型在 20 帧中的几帧中没有识别出“ONE”姿势。max_missing_frames是允许丢失的帧数的最大值,超出该值,当前手势结束。
下面举几个例子说明使用方法,更多高级手势可以由读者根据手势控制信号和4种控制模式自由组合而成(如单手单手势+多轨迹的组合,单手0多手势+时序组合判断等)。
- 挥手下一个节目。采用enter_leave模式,基础手势为”OPEN“,触发两个事件,判断手势开始时的”rotation“是否在(-1.5, -0.3)内,手势结束时的”rotation“是否在(0.3, 1.5)内,max_missing_frames设置为较大值10,即允许挥动过程中的较长时间的漏检误检。结束的时候握拳,即结束该手势信号,如果想中断该信号,则将手旋转至(0.6, 2.0)区间外结束手势即可。
- 连续调节音量。采用period模式,基础手势为左手”TWO“,右手“ONE”,手向左倾持续减小音量,向右倾则持续增加音量。
- “Blink”控制。采用entrer模式,基础手势为左手“OPEN”,通过累计触发次数来判断是否发出信号,累计次数为2,最短间隔为40帧。作为对比,我们首先慢速切换手势,无信号发出;快速“Blink”,信号发出。
 挥手控制
挥手控制
 组合手势控制音量
组合手势控制音量
 慢速手势
慢速手势
 Blink
Blink
家居的智能控制比较简单,可以直接在回调函数中调用相关api进行控制,如此例中的Sony Bravia电视5。也可以通过Node-Red、n8n、Home Assistant中的无代码组件设置触发流程。
代码示例中,提供了一个flask api服务,调用可以暂停或恢复服务,以降低能耗或在特定情况下避免误触发:如人离家时,通过小米无线按钮,暂停服务;如人在家健身时,肢体变化较大,可能造成控制信号的误触发,需要暂停服务。当然,还有更多的切换方式,如通过人体存在传感器切换服务,或使用其它智能语音切换服务,或通过特定手势暂停服务,或通过无检测阈值暂停服务等等。
展望 #
考虑到项目的独立性,同时时间有限,有很多想法没融入到该项目中,欢迎大家一起讨论。
Github
osnsyc/Gesture-Based-Home-Automation
- 空间定位的精度不高,如果需要更高精度的人体定位,贵的方法就是用双目相机,便宜的方案我觉得可以加一个毫米波雷达定位人体。但毫米波雷达方案和单目方案都有一个缺陷:手部深度默认与人体是一致的(即处于同一个平面),比如我需要在地面(xz平面)画一个区域让机器人清扫,则无法实现;
- 也许可以通过3D人体姿态来重定位手部位置;我们在手部检测阶段同时检测了头部,如果加一个头部的姿态估计模型获取人脸朝向,可能可以做到”指哪打哪“、”看哪打哪“;6
- 边缘设备的安装。新家做了无主灯,每个房间都有可供电的48V轨道,我计划在轨道上做一个20W转接口,将香橙派上墙,更加美观,俯拍可以更好地避免遮挡和逆光;
- 该项目的资源占用不算高,人体检测约NPU单核12%,手势检测约NPU3核32%,感觉还有资源可以在多个房间同时部署,视频通过rtsp串流到同一个香橙派上,当然串流会带来更大的延迟。
- 依赖光学图像进行识别,在低照度下,有些相机会提高曝光时间、降低帧率,可能会影响体验,同时,极低照度环境功能失效。
-
最接近我设想功能的是 geaxgx/depthai_hand_tracker项目,这是一个运行在OAK深度相机上的手势控制项目,但它依赖Mediapipe和Movenet,只支持单人场景,并且识别帧率不高。 ↩︎
-
为数学意义上的无穷 ↩︎
-
Orange Pi 5 Pro Orange Pi官网-香橙派(Orange Pi)开发板,开源硬件,开源软件,开源芯片,电脑键盘 ↩︎
-
GitHub - Kazuhito00/hand-gesture-recognition-using-mediapipe: MediaPipe(Python版)を用いて手の姿勢推定を行い、検出したキーポイントを用いて、簡易なMLPでハンドサインとフィンガージェスチャーを認識するサンプルプログラムです。(Estimate hand pose using MediaPipe(Python version). This is a sample program that recognizes hand signs and finger gestures with a simple MLP using the detected key points.) ↩︎
-
PINTO_model_zoo/423_6DRepNet360 at main · PINTO0309/PINTO_model_zoo · GitHub, GitHub - thohemp/6DRepNet360: Official Pytorch implementation of “Towards Robust and Unconstrained Full Range of Rotation Head Pose Estimation” IEEE TIP 24 ↩︎