
前言 #
这几年我一直使用HOOK的方案来获取微信公众号的推送,得益于HOOK的原理,只要微信客户端在线,消息从无遗漏,并且是实时的。由此,也筛选出了“学术类微信公众号”,每日3个时间点定时更新至 GitHub - osnsyc/Wechat-Scholar仓库。但最近HOOK的方案开始不稳定,可能是由于运行环境或者微信版本的问题遭到风控,每日定时被强制下线,虽然只要再次点击登录且仍可收到短暂下线时段的公众号消息,但是,是时候找个备用的方案了。
HOOK方案风险是比较大的,且需要对特定版本单独维护,时间精力成本比较高。微信V3版本对数据的写入不频繁,经常是退出微信后才进行一次数据库更新,而微信V4版本更新后,对数据库的写入更加频繁,几乎是“实时”的,这使我们直接从本地数据库解析公众号消息成为了可能。
微信本地数据库文件是一组加密后的 SQLCipher 文件,由腾讯的 WCDB 项目 支持。 SQLCipher 的机制是以增加 10-15% 的开销,100% 加密本地的 SQLite 文件,并提供与 SQLite 相同的 API。 首次在设备登录微信时,会计算出一组密钥用于加密本地的数据库文件,这组密钥在每个账户、每台设备上都是不一样的。 在同账号同设备上更换密钥的频率不高,更换密钥意味着需要对全部数据重新加密,重度使用的微信账号数据量不小,所以一般是微信大版本更新时更换密钥。1
开源社区已经有了很多微信数据库解密的项目,如:
- GitHub - 0xlane/wechat-dump-rs
- GitHub - sjzar/chatlog
- GitHub - xaoyaoo/PyWxDump
- GitHub - kanadeblisst00/pywxrobot2.0
- GitHub - git-jiadong/wechatDataBackup
这些项目一般也集成了密钥的计算,未来的版本除了通过内存数据暴力搜索,也可以通过HOOK获取,但相比之前对整个微信的HOOK(多用于构建机器人),这类方案不修改、不注入dll文件(或只在特定阶段进行),会更加安全一些。
若想尝试以下内容,请自行承担可能的封号风险。
数据库结构 #
微信数据库路径一般为C:\Users\{系统用户名}\Documents\WeChat Files\{微信ID},重点关注db_storage/message/biz_message_0.db和db_storage/contact/contact.db,里面有我们要获取的所有信息。
db_storage/message/biz_message_0.db存储了已关注的公众号消息记录,结构如下:
CREATE TABLE DeleteInfo(chat_name_id INTEGER, delete_table_name TEXT, CONSTRAINT UNIQUE_CHAT_DELETE UNIQUE(chat_name_id, delete_table_name))
CREATE TABLE DeleteResInfo(local_id INTEGER PRIMARY KEY AUTOINCREMENT, session_name_id INTEGER, msg_create_time INTEGER, msg_local_id INTEGER, res_path TEXT)
CREATE TABLE Msg_02628fb4b062917ee2a9d4d7bde609ad(local_id INTEGER PRIMARY KEY AUTOINCREMENT, server_id INTEGER, local_type INTEGER, sort_seq INTEGER, real_sender_id INTEGER, create_time INTEGER, status INTEGER, upload_status INTEGER, download_status INTEGER, server_seq INTEGER, origin_source INTEGER, source TEXT, message_content TEXT, compress_content TEXT, packed_info_data BLOB, WCDB_CT_message_content INTEGER DEFAULT NULL, WCDB_CT_source INTEGER DEFAULT NULL)
CREATE TABLE Name2Id(user_name TEXT PRIMARY KEY)
CREATE TABLE TimeStamp(timestamp INTEGER)
CREATE TABLE sqlite_sequence(name,seq)
CREATE TABLE wcdb_builtin_compression_record(tableName TEXT PRIMARY KEY, columns TEXT NOT NULL, rowid INTEGER) WITHOUT ROWID
CREATE INDEX DeleteInfo_CINDEX ON DeleteInfo(chat_name_id)
CREATE INDEX DeleteInfo_DINDEX ON DeleteInfo(delete_table_name)
CREATE INDEX DeleteResInfo_SCLINDEX ON DeleteResInfo(session_name_id, msg_create_time, msg_local_id)
CREATE INDEX Msg_02628fb4b062917ee2a9d4d7bde609ad_SENDERID ON Msg_02628fb4b062917ee2a9d4d7bde609ad(real_sender_id)
CREATE INDEX Msg_02628fb4b062917ee2a9d4d7bde609ad_SERVERID ON Msg_02628fb4b062917ee2a9d4d7bde609ad(server_id)
CREATE INDEX Msg_02628fb4b062917ee2a9d4d7bde609ad_SORTSEQ ON Msg_02628fb4b062917ee2a9d4d7bde609ad(sort_seq)
CREATE INDEX Msg_02628fb4b062917ee2a9d4d7bde609ad_TYPE_SEQ ON Msg_02628fb4b062917ee2a9d4d7bde609ad(local_type, sort_seq)
数据中的local_type关联了消息类型,在公众号中,一般为1-文本消息和21474836529-图文消息,文本消息一般为关注时的提醒或消息通知,图文消息则是我们要获取的推文,在message_content中,为zstd压缩的文件。
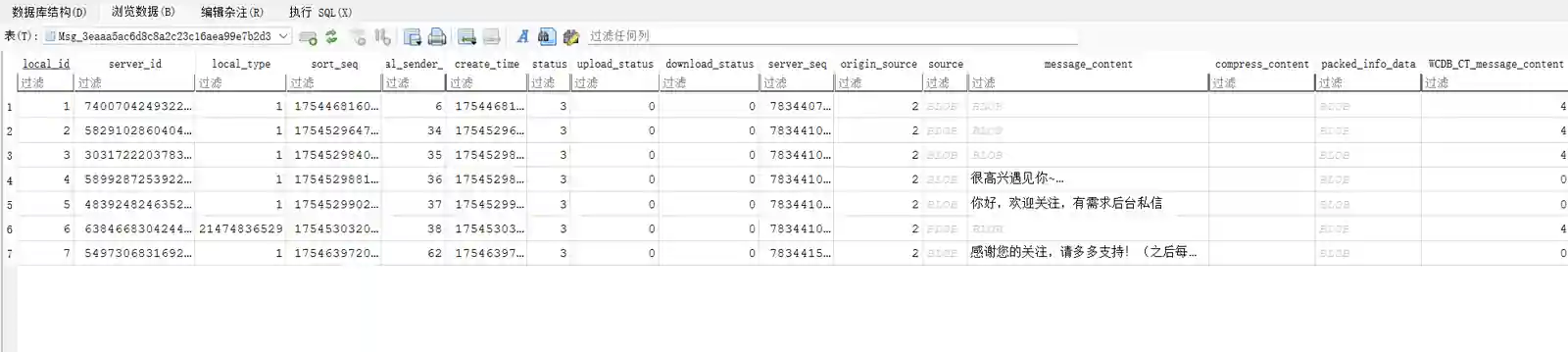 解密后的数据库
解密后的数据库
local_type |
消息类型 | message_content格式 |
|---|---|---|
| 1 | 文本消息 | plain |
| 3 | 图片消息 | zstd_compress(xml) |
| 34 | 语音消息 | zstd_compress |
| 42 | 名片消息 | zstd_compress |
| 43 | 视频消息 | zstd_compress |
| 47 | 动画表情 | zstd_compress(xml) |
| 48 | 位置消息 | zstd_compress |
| 244813135921 | 引用消息 | zstd_compress(xml) |
| 17179869233 | 卡片式链接(带描述) | zstd_compress(xml) |
| 21474836529 | 卡片式链接/图文消息 | zstd_compress(xml) |
| 154618822705 | 小程序分享 | zstd_compress(xml) |
| 12884901937 | 音乐卡片 | zstd_compress |
| 8594229559345 | 红包卡片 | zstd_compress |
| 81604378673 | 聊天记录合并转发消息 | zstd_compress |
| 266287972401 | 拍一拍消息 | zstd_compress |
| 8589934592049 | 转账卡片 | zstd_compress |
| 270582939697 | 视频号直播卡片 | zstd_compress |
| 25769803825 | 文件消息 | zstd_compress |
| 10000 | 系统消息(撤回、加入群聊、群管理、群语音通话等) | plain or zstd_compress(xml) |
将message_content解压缩后,得到如下格式的消息,fromusername为gh_若干位字母数字组合或wxid_若干位纯数字(常见于注册时间早的公众号)即公众号的唯一id,也是区别于其它应用消息、服务号的方法。mmreader中包含了完整的标题、链接、摘要、封面图片链接、发布时间等信息,读取出来整理成RSS格式。
<msg>
<appmsg appid="" sdkver="0">
<title><![CDATA[文章标题]]></title> <!-- 文章标题 -->
<des><![CDATA[文章摘要]]></des> <!-- 文章描述/摘要 -->
<type>5</type> <!-- 消息类型,5通常是图文消息 -->
<url><![CDATA[文章链接]]></url> <!-- 文章跳转链接 -->
<appattach>...</appattach> <!-- 附件信息,图文一般为空 -->
<mmreader>
<category type="20" count="2"> <!-- 分类、数量 -->
<item> <!-- 单篇文章条目 -->
<title><![CDATA[条目标题]]></title>
<url><![CDATA[条目链接]]></url>
<summary><![CDATA[条目摘要]]></summary>
<cover><![CDATA[封面图片URL]]></cover>
...
</item>
<!-- 可能多个item表示多篇图文 -->
</category>
<publisher>
<username><![CDATA[公众号ID]]></username>
<nickname><![CDATA[公众号昵称]]></nickname>
</publisher>
</mmreader>
<thumburl><![CDATA[缩略图URL]]></thumburl>
</appmsg>
<fromusername><![CDATA[公众号ID]]></fromusername> <!-- 来源公众号 -->
<appinfo>
<appname><![CDATA[公众号名]]></appname> <!-- 公众号名称 -->
...
</appinfo>
</msg>
db_storage/contact/contact.db是联系人数据库,包括在微信里你能看到的各种群、群成员、通讯录、公众号的信息。我们获取small_head_url字段内容,如http://wx.qlogo.cn/xxxxxxxxxx作为RSS channel中的头像。
CREATE TABLE contact(id INTEGER PRIMARY KEY, username TEXT, local_type INTEGER, alias TEXT, encrypt_username TEXT, flag INTEGER, delete_flag INTEGER, verify_flag INTEGER, remark TEXT, remark_quan_pin TEXT, remark_pin_yin_initial TEXT, nick_name TEXT, pin_yin_initial TEXT, quan_pin TEXT, big_head_url TEXT, small_head_url TEXT, head_img_md5 TEXT, chat_room_notify INTEGER, is_in_chat_room INTEGER, description TEXT, extra_buffer BLOB, chat_room_type INTEGER)
在Linux中部署Windows和微信4.0 #
同HOOK方案类似,需要微信客户端常驻才能不遗漏地接收公众号的推送2。理论上Linux v4的数据和Windows v4的数据格式现在可以共通使用3,但相关的工具目前大多基于Windows或MacOS的。还是暂时适配一个Windows环境,用 dockur/windows起一个Win11的容器。
# docker-compose.yml
services:
windows:
image: dockurr/windows:latest
container_name: windows
environment:
VERSION: "11"
USERNAME: "xxx"
PASSWORD: "1"
LANGUAGE: "Chinese"
devices:
- /dev/kvm
- /dev/net/tun
cap_add:
- NET_ADMIN
ports:
- 5030:5030
- 8006:8006
- 3389:3389/tcp
- 3389:3389/udp
volumes:
- ./windows:/storage
- ./shared:/data
- ./install:/oem
restart: always
stop_grace_period: 2m
8006是VNC的端口,Web直接访问连接桌面,但是缩放和访问速度都欠佳,用RDP连接效果好很多,服务器地址填宿主机IP即可(保持3389端口不变的情况下);/data可以映射到宿主机上实现文件的互通,打开"文件资源管理器",点击"网络"部分,会看到一个名为host.lan的电脑,用映射网络驱动器挂载到Z:盘;/oem,容器安装的最后会自动安装/oem下的软件,将微信的安装包(版本<4.0.3.36)放置在此处,同时也把chatlog.exe放进去,并新建install.bat,内容如下:
@echo off
echo Installing WeChat 4.0.3.36...
start /wait "" "%~dp0weixin_4.0.3.36.exe" /S
echo Installation complete!
- 屏蔽更新通道,修改
hosts:127.0.0.1 dldir1.qq.com
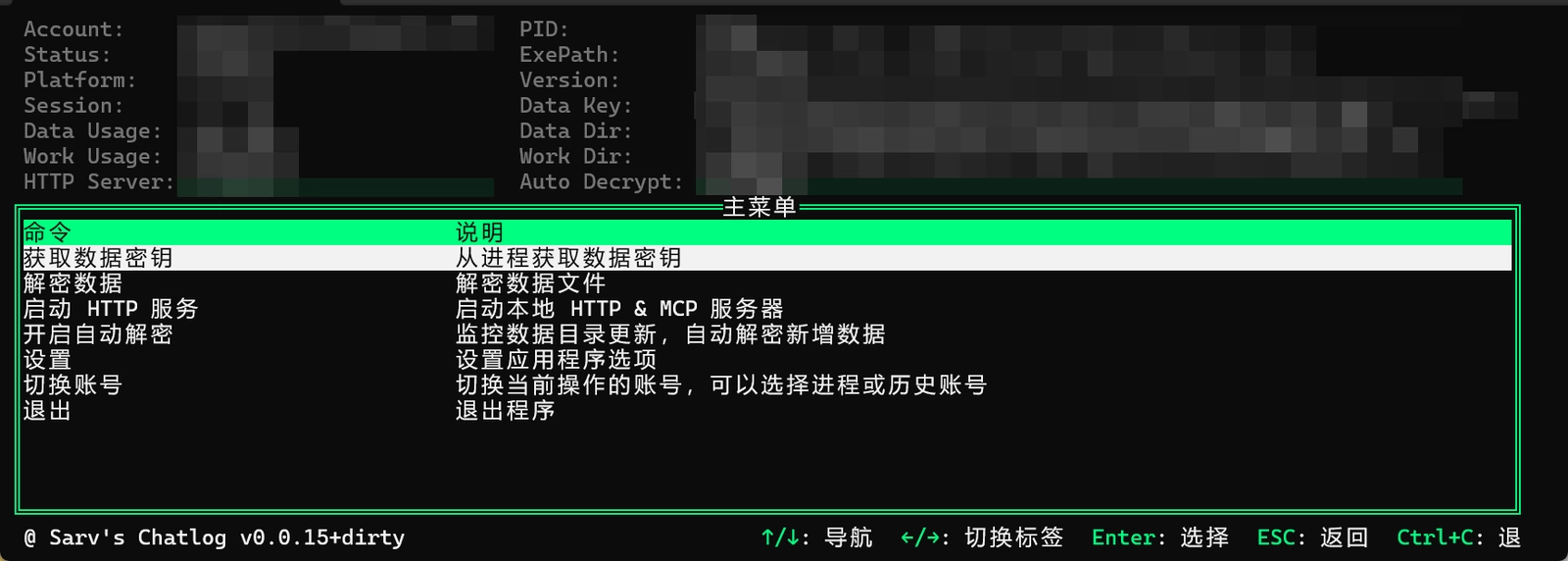 chatlog
chatlog
使用
sjzar/chatlog作为解密的工具。在Win11中运行微信(完成登录)和chatlog.exe,在chatlog中:
- 点击
获取数据密钥,等待密钥的搜寻; - 在
设置中配置数据解密密钥并保存; - 在
配置数据解密后的存储目录为Z:\wechat,这里面的数据会映射至宿主机,供我们后续处理; - 返回主菜单,点击
解密数据完成第一次解密,然后可以打开开启自动解密,一旦微信数据有更新,程序会自动解密并在Z:\wechat中覆盖原解密数据。
此外,也可以通过PowerShell命令行操作,仅解密指定的数据:
# 获取数据密钥,将打印密钥
chatlog.exe key
# 仅解密biz_message_0.db
chatlog.exe decrypt -d C:\Users\{YOUR_NAME}\xwechat_files\{YOUR_ID}\db_storage\message\biz_message_0.db -w Z:\wechat\biz_message_0.db -k {YOUR_KEY} -v 4
# 可开启HTTP MCP服务器
chatlog.exe server -w Z:\wechat -v 4
定期运行以下脚本db2rss.py,即可将message_content中的数据转换为RSS格式。根据实际情况配置DB_PATH,CACHE_DB,OUTPUT_DIR。
import os
import re
import sqlite3
import argparse
from typing import Optional
from datetime import datetime, timezone, timedelta
from email.utils import format_datetime
from xml.dom import minidom
import xml.etree.ElementTree as ET
import zstandard as zstd
DB_PATH = "../shared/wechat"
CACHE_DB = "cache.db"
OUTPUT_DIR = "source_xml"
LOCAL_TYPE_FILTER = 21474836529
ZSTD_MAGIC = b"\x28\xb5\x2f\xfd"
BIZ_DB = os.path.join(DB_PATH, "db_storage/message/biz_message_0.db")
CONTACT_DB = os.path.join(DB_PATH, "db_storage/contact/contact.db")
os.makedirs(OUTPUT_DIR, exist_ok=True)
def decompress_if_needed(data: bytes) -> Optional[str]:
if data.startswith(ZSTD_MAGIC):
try:
return zstd.ZstdDecompressor().decompress(data).decode("utf-8", errors="ignore")
except Exception:
return None
return data.decode("utf-8", errors="ignore")
def partial_unescape(text: str) -> Optional[str]:
return (
text.replace("<", "<")
.replace(">", ">")
.replace(""", '"')
.replace("'", "'")
)
def add_cdata(parent, tag, text):
e = ET.SubElement(parent, tag)
e.text = f"<![CDATA[{text}]]>"
def update_rss(xml_string: str):
try:
root = ET.fromstring(xml_string)
username = root.findtext(".//publisher/username")
nickname = root.findtext(".//publisher/nickname", default="公众号文章")
items = root.findall(".//category/item")
if not username or not items:
return
rss = ET.Element("rss", version="2.0", attrib={"xmlns:atom": "http://www.w3.org/2005/Atom"})
channel = ET.SubElement(rss, "channel")
add_cdata(channel, "title", nickname)
ET.SubElement(channel, "link").text = "https://mp.weixin.qq.com/"
add_cdata(channel, "description", f"{nickname}公众号")
ET.SubElement(channel, "language").text = "zh-cn"
image = ET.SubElement(channel, "image")
ET.SubElement(image, "url").text = f"icon/{username}.jpg"
ET.SubElement(image, "title").text = username
for item in items:
title = re.sub(r"\s+", " ", (item.findtext("title") or "无标题").strip())
link = item.findtext("url") or ""
cover = item.findtext("cover") or ""
summary_raw = item.findtext("summary") or item.findtext("digest") or ""
summary = re.sub(r"\s+", " ", summary_raw.strip())
desc = f'<img referrerpolicy="no-referrer" src="{cover}"/><p>{summary}</p>' if cover else f"<p>{summary}</p>"
try:
pub_time = int(item.findtext("pub_time"))
pub_date = datetime.fromtimestamp(pub_time, tz=timezone(timedelta(hours=8)))
except Exception:
pub_date = datetime.now(tz=timezone(timedelta(hours=8)))
rss_item = ET.SubElement(channel, "item")
add_cdata(rss_item, "title", title)
add_cdata(rss_item, "description", desc)
ET.SubElement(rss_item, "link").text = link
ET.SubElement(rss_item, "pubDate").text = format_datetime(pub_date)
xml_final = minidom.parseString(ET.tostring(rss, encoding="utf-8")).toprettyxml(indent=" ", encoding="utf-8").decode("utf-8")
xml_final = partial_unescape(xml_final)
xml_final = "\n".join([line for line in xml_final.splitlines() if line.strip()])
rss_path = os.path.join(OUTPUT_DIR, f"{username}.xml")
if os.path.exists(rss_path):
with open(rss_path, encoding="utf-8") as f:
old = f.read()
old_image_match = re.search(r"<image>\s*<url>(.*?)</url>", old, re.DOTALL)
if old_image_match:
old_url = old_image_match.group(1).strip()
xml_final = re.sub(r"(<image>\s*<url>).*?(</url>)", rf"\1{old_url}\2", xml_final, flags=re.DOTALL)
old_items = re.findall(r"<item>.*?</item>", old, re.DOTALL)
new_items = re.findall(r"<item>.*?</item>", xml_final, re.DOTALL)
merged = new_items + [i for i in old_items if i not in new_items]
merged = merged[:50]
xml_final = re.sub(
r"(<channel>.*?)(<item>.*?</item>\s*)+(.*?</channel>)",
lambda m: m.group(1) + "\n".join(merged) + "\n" + m.group(3),
xml_final,
flags=re.DOTALL
)
dom = minidom.parseString(xml_final.encode("utf-8"))
pretty_xml_str = dom.toprettyxml(indent=" ")
xml_final_str = partial_unescape(pretty_xml_str)
xml_final_str = "\n".join([line for line in xml_final_str.splitlines() if line.strip()])
with open(rss_path, "w", encoding="utf-8") as f:
f.write(xml_final_str)
print(f"[+] 更新 {username} - {nickname}, 数量: {len(items)}")
except ET.ParseError as e:
print(f"[!] XML解析失败: {e}")
def update_avatar_urls():
conn = sqlite3.connect(CONTACT_DB)
cursor = conn.cursor()
cursor.execute("SELECT username, small_head_url FROM contact")
avatar_map = dict(cursor.fetchall())
conn.close()
for fname in os.listdir(OUTPUT_DIR):
if not fname.endswith(".xml"):
continue
path = os.path.join(OUTPUT_DIR, fname)
uname = os.path.splitext(fname)[0]
if uname not in avatar_map:
continue
with open(path, encoding="utf-8") as f:
content = f.read()
match = re.search(r"<image>\s*<url>(.*?)</url>", content)
if match and match.group(1).strip() != avatar_map[uname]:
print(f"[+] 更新 {fname} 的头像 URL")
content = re.sub(r"(<image>\s*<url>).*?(</url>)", rf"\1{avatar_map[uname]}\2", content, flags=re.DOTALL)
with open(path, "w", encoding="utf-8") as f:
f.write(content)
def update_rss_feeds():
cache_conn = sqlite3.connect(CACHE_DB)
cache_cursor = cache_conn.cursor()
cache_cursor.execute("CREATE TABLE IF NOT EXISTS table_sequence (name TEXT PRIMARY KEY, seq INTEGER)")
cache_cursor.execute("CREATE TABLE IF NOT EXISTS check_log (id INTEGER PRIMARY KEY, timestamp INTEGER)")
cache_conn.commit()
cache_cursor.execute("SELECT MAX(timestamp) FROM check_log")
last_check = cache_cursor.fetchone()[0] or 0
biz_conn = sqlite3.connect(BIZ_DB)
biz_cursor = biz_conn.cursor()
biz_cursor.execute("SELECT name, seq FROM sqlite_sequence")
biz_seq = dict(biz_cursor.fetchall())
cache_cursor.execute("SELECT name, seq FROM table_sequence")
cache_seq = dict(cache_cursor.fetchall())
changed = [name for name in biz_seq if biz_seq[name] != cache_seq.get(name)] # 防止KeyError
for name in changed:
cache_cursor.execute("REPLACE INTO table_sequence (name, seq) VALUES (?, ?)", (name, biz_seq[name]))
latest_timestamp = last_check
#TODO 尚不清楚数据表格是否会被删除或重命名,不清楚deleteinfo的触发条件,先采用遍历全部表格的方式
# for name in changed:
all_name = [name for name in biz_seq]
for name in all_name:
try:
if last_check:
sql = f"""SELECT message_content, create_time
FROM "{name}"
WHERE local_type = ? AND create_time > ?"""
params = (LOCAL_TYPE_FILTER, last_check)
else:
sql = f"""SELECT message_content, create_time
FROM "{name}"
WHERE local_type = ?"""
params = (LOCAL_TYPE_FILTER,)
biz_cursor.execute(sql, params)
for msg, create_time in biz_cursor.fetchall():
if create_time > latest_timestamp:
latest_timestamp = create_time
xml = decompress_if_needed(msg)
if xml and "<msg>" in xml:
update_rss(xml)
except Exception as e:
print(f"[!] 处理 {name} 时出错: {e}")
if latest_timestamp > last_check:
cache_cursor.execute("INSERT INTO check_log (timestamp) VALUES (?)", (latest_timestamp,))
cache_conn.commit()
biz_conn.close()
cache_conn.close()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--func", choices=["rss", "avatar", "all"], default="all", help="执行模式")
args = parser.parse_args()
if args.func in ("rss", "all"):
update_rss_feeds()
if args.func in ("avatar", "all"):
update_avatar_urls()
运行db2rss.py,将初始化一个cache.db数据库,用于比对数据和记录操作时间戳。RSS格式的订阅文件将自动增量更新并保存于source_xml文件夹内。
python db2rss.py --func rss # 仅更新rss条目
python db2rss.py --func avatar # 仅更新头像
python db2rss.py # 同时更新rss和头像
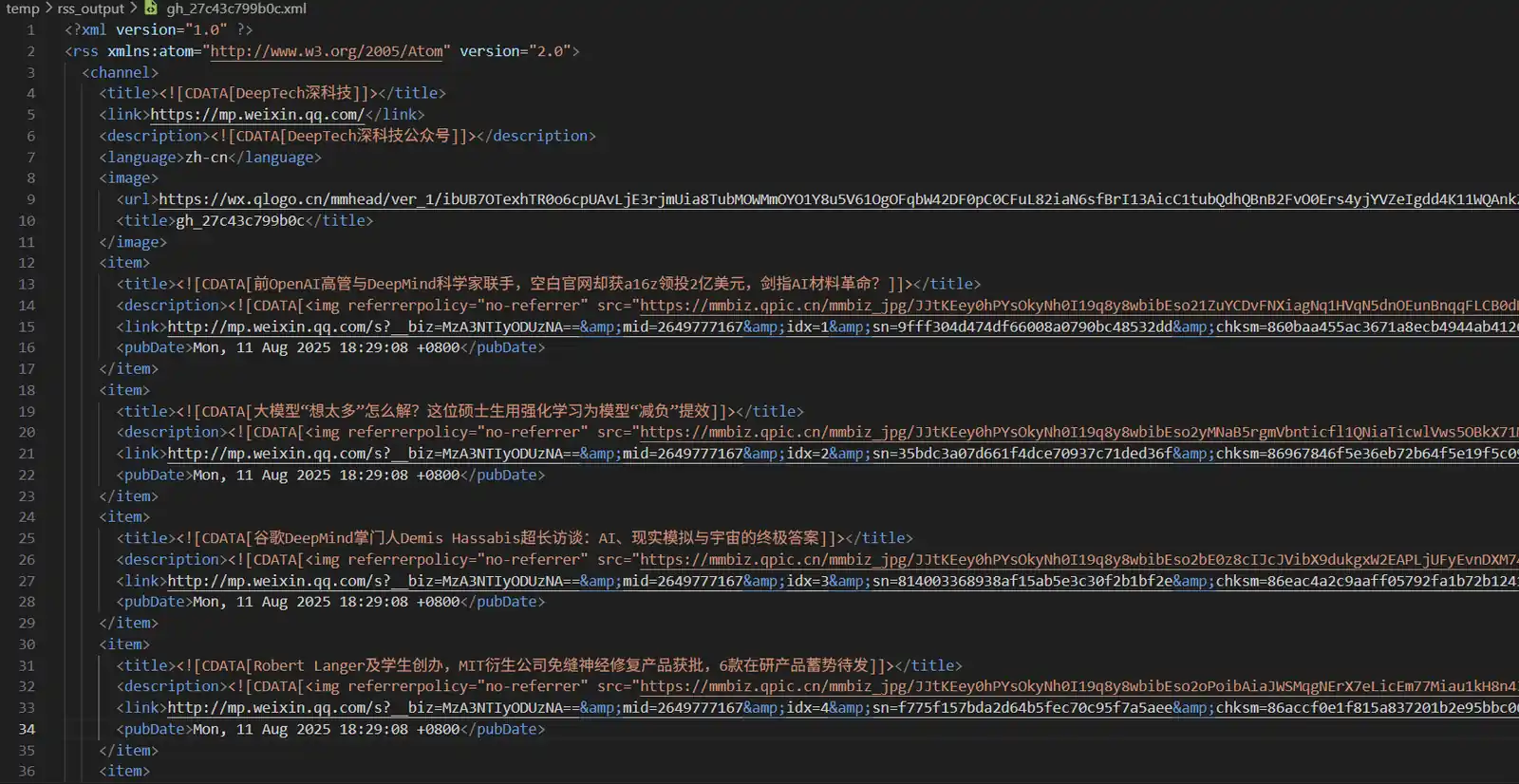 RSS文件示例
RSS文件示例
相关阅读 #
- 微信聊天记录解密 | Sarv’s Blog
- 合适的微信版本(windows x macos)以及常见问题 · Issue #131 · sjzar/chatlog
- wechat-dump-rs/docs 微信4.0分析
- wechat-dump-rs/docs 微信4.0数据库结构
-
最多尝试了离线3天后,再次上线还能接收部分前1~2日的推送。 ↩︎